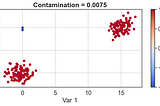
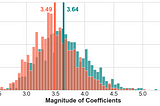
PinnedPublished inAnalytics VidhyaLess known Applications of k-Means Clustering — Dimensionality Reduction, Anomaly Detection and…Distance of data points from the cluster centers can be used as engineered features. This allows us to heavily reduce the number of…Jul 9, 2021Jul 9, 2021
PinnedPublished inTDS ArchiveAnomaly Detection in Python — Part 2; Multivariate Unsupervised Methods and CodeIn this article, we will discuss Isolation Forests and One Class SVM to perform Multivariate Unsupervised Anomaly Detection along with codeMay 22, 2021May 22, 2021
Published inAnalytics VidhyaAnomaly Detection in Python — Part 1; Basics, Code and Standard AlgorithmsMay 11, 20214May 11, 20214
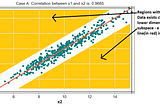
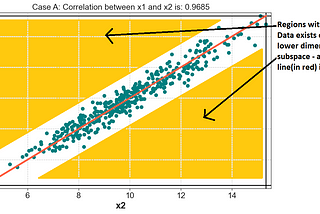
Published inAnalytics VidhyaPrincipal Component Analysis (PCA)— Part 1 — Fundamentals and ApplicationsPCA works due to Linear dependence(Collinearity) among features. Linear Dependence, forces data to lie along lower dimensional Planes.Feb 17, 2021Feb 17, 2021
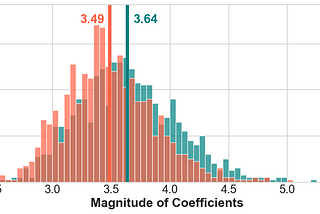
Published inAnalytics VidhyaRidge Regression: Regularization FundamentalsRegularization is a method used to reduce the variance of a Machine Learning model; in other words, it is used to reduce overfitting…Jun 14, 2020Jun 14, 2020
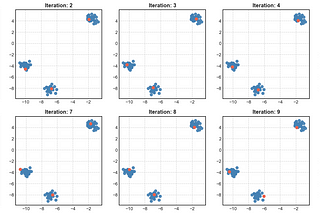
Published inAnalytics VidhyaComparison of Initialization strategies for k-Meansk-Means is a data partitioning algorithm which is among the most immediate choices as a clustering algorithm. Some reasons for the…Apr 11, 20201Apr 11, 20201